import pandas as pd # 导入Pandas,用于数据读取和处理
# 从本地目录读取房价数据
df_housing = pd.read_csv("house.csv")
# 显示加州房价数据的前5行
df_housing.head()
下面我来为你详细解释这段Python代码的含义、实现原理、用途以及使用时的注意事项。
### 一、 代码整体含义
这段代码的主要功能是**使用Pandas库从本地读取一个名为"house.csv"的房价数据集,并预览该数据集的前5行内容**。这是数据分析和机器学习任务中最基础、最典型的第一步——数据加载与初步探查。
---
### 二、 逐行代码解析与实现原理
1. *import pandas as pd**
- 含义:导入Pandas库,并给它起一个别名 pd。
- 原理:Pandas是Python中最强大的数据分析和操作库。它基于NumPy构建,核心引入了两种数据结构:Series(一维数据)和DataFrame(二维数据表)。起别名 pd 是社区约定俗成的规范,可以减少代码书写量。
2. *df_housing = pd.read_csv("house.csv")**
- 含义:读取当前工作目录下名为 house.csv 的文件,并将读取的数据赋值给变量 df_housing。
- 原理:
- pd.read_csv() 是Pandas提供的文本文件读取函数。它底层使用C语言优化过的解析器,能够高效地将CSV(逗号分隔值)文件的内容解析成一个DataFrame二维表格。
- df_housing 中的 df 是DataFrame的缩写housing 表明这是房价数据,这种命名方式提高了代码的可读性。
3. *df_housing.head()**
- 含义:打印并显示 df_housing 数据框的前5行数据。
- 原理head() 是DataFrame对象的内置方法,默认参数为5。它返回一个新的DataFrame,包含原数据的前n行。这基于计算机科学中的“分治/抽样”思想,不需要加载和渲染全部数据即可快速了解数据的结构。
---
### 三、 用途
这段代码在数据科学工作流中有以下典型用途:
1. 数据加载:将持久化在硬盘上的数据加载到内存中,以便后续进行清洗、分析或建模。
2. 数据初探:通过查看前5行,可以快速确认:
- 数据是否读取成功(有没有乱码或错位)。
- 列名是什么(特征名称,如房间数、经纬度、房价中位数等)。
- 数据的大致类型(是数值型还是字符串型)。
- 是否存在明显的缺失值或异常值。
---
### 四、 注意事项(非常重要)
在实际运行这段代码时,有几个关键点需要注意:
1. 文件路径问题(最常见报错):
- pd.read_csv("house.csv") 使用的是相对路径。这意味着 house.csv 必须位于**Python脚本运行的当前工作目录**下,否则会抛出 FileNotFoundError。
- 建议:如果文件不在当前目录,应使用绝对路径,如 pd.read_csv("C:/Users/YourName/Data/house.csv")。注意在Windows下路径斜杠的方向,推荐使用正斜杠 / 或在字符串前加 r(如 r"C:\Users\...")。
2. CSV文件的编码格式:
- 默认情况下read_csv 使用UTF-8编码。如果你的CSV文件是由Excel保存的,它可能是GBK或GB2312编码,读取时会报 UnicodeDecodeError。
- 解决方法:指定编码参数,如 pd.read_csv("house.csv", encoding='gbk')。
3. 分隔符问题:
- 虽然文件后缀是 .csv,但有些文件内部可能使用空格、制表符或分号作为分隔符。如果分隔符不对,数据会挤在一列里。
- 解决方法:指定分隔符参数,如 pd.read_csv("house.csv", sep='\t') 或 delimiter=';'。
4. Jupyter Notebook环境下的显示:
- 如果你是在Jupyter Notebook中运行df_housing.head() 会以美观的HTML表格形式渲染输出。
- 如果你是在普通的 .py 脚本或终端中运行,仅仅写 df_housing.head() 在Python 3中是**不会在屏幕上打印出内容的**。你需要加上 print() 函数,即 print(df_housing.head()),不过这样输出的是纯文本对齐的表格,不如Jupyter美观。
5. 内存限制:
- read_csv 会将数据全部加载到内存中。如果 house.csv 文件非常大(例如几十GB),会导致内存溢出(OOM)。
- 解决方法:可以使用 chunksize 参数分块读取,例如 pd.read_csv("house.csv", chunksize=10000),这会返回一个可迭代对象。
希望这个详细的解释对你理解这段代码有所帮助!如果你有任何后续的数据处理需求,随时可以问我。

X = df_housing.drop("median_house_value",axis = 1) #构建特征集X
y = df_housing.median_house_value #构建标签集y下面我来为你详细解释这段Python代码的含义、实现原理、用途以及注意事项。
### 一、 代码含义
这段代码是机器学习数据预处理阶段非常经典且核心的操作——**分离特征变量(自变量)与标签变量(因变量)**。
* 第一行:从数据集 df_housing 中删除名为 "median_house_value" 的列(即房屋中位数价值),将剩余的所有列赋值给变量 X,作为特征集。
* 第二行:从数据集 df_housing 中单独提取出 "median_house_value" 这一列,赋值给变量 y,作为标签集。
### 二、 实现原理
这段代码基于 Python 的数据分析库 pandas 实现df_housing 通常是一个 pandas.DataFrame 对象。
1. *df_housing.drop("median_house_value", axis = 1)**:
* drop 是 DataFrame 的方法,用于删除指定的行或列。
* "median_house_value" 指定了要删除的列名。
axis = 1 是关键参数,表示*按列删除**(即垂直方向删除整列)。如果 axis = 0 则表示按行删除。执行后,返回的是一个不包含该列的新 DataFrame。
2. *df_housing.median_house_value**:
* 这是 pandas 提供的一种语法糖(属性访问方式),用于提取指定列的数据。
* 它等价于 df_housing["median_house_value"]。执行后,返回的是一个 pandas.Series 对象。
### 三、 用途
这段代码主要用于**监督学习**的模型训练准备阶段。
在房价预测等回归问题中,我们的目标是利用房屋的各种特征(如经纬度、房龄、房间数等)来预测房屋的价格。
* *X(特征集)**:包含了用于预测的输入信息。在数学模型中,它对应自变量。模型通过学习 X 中的模式来进行预测。
* *y(标签集)**:包含了我们需要预测的真实结果。在数学模型中,它对应因变量。模型会计算预测值与 y 的误差来优化自身。
将两者分离是因为 scikit-learn 等机器学习库的 API 标准格式通常为model.fit(X, y),即要求特征和标签作为两个独立的参数传入。
### 四、 注意事项
1. *drop 方法不会修改原数据**:
drop 操作默认是**非原地**的,它会返回一个删除了指定列的新对象,而不会改变原始的 df_housing。如果希望直接在原数据上修改,需要添加 inplace=True 参数,即 df_housing.drop("median_house_value", axis=1, inplace=True)。但在本例中,由于我们需要保留原数据以便提取 y,所以**不应**使用 inplace=True。
2. 大小写规范:
在机器学习的代码规范中,通常使用**大写的 X** 表示特征矩阵(因为它是二维矩阵,通常包含多个特征),使用**小写的 y** 表示标签向量(因为它是单列的一维向量)。遵循此规范可以提高代码的可读性。
3. 数据对齐问题:
分离后的 X 和 y 依然保留着 pandas 的索引。在后续操作中(如划分训练集和测试集,或者模型预测),必须确保 X 和 y 的索引是一一对应的,否则会导致特征和标签错位,模型学到错误的关系。
4. 目标列的存在性:
执行代码前,需确保 df_housing 中确实存在 "median_house_value" 这个列名,否则 drop 和属性访问都会报错 KeyError。
希望这个解释对你理解这段代码有所帮助!如果你还有其他关于机器学习或 pandas 操作的问题,随时可以问我。
from sklearn.model_selection import train_test_split #导入数据集拆分工具
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2, random_state=0) #以80%/20%的比例进行数据集的拆分你好!我是CodeGeeX。下面为你详细解释这段Python代码的含义、实现原理、用途以及使用时的注意事项。
### 1. 代码含义
这段代码使用了机器学习库 scikit-learn 中的 train_test_split 函数,将特征数据集 X 和标签数据集 y 拆分成了四个部分:
* *X_train**: 训练集特征(占80%),用于训练模型。
* *X_test**: 测试集特征(占20%),用于评估模型。
* *y_train**: 训练集标签(占80%),与 X_train 一一对应。
* *y_test**: 测试集标签(占20%),与 X_test 一一对应。
### 2. 实现原理
train_test_split 的核心原理是**随机抽样**:
1. 数据对齐:函数首先确保 X 和 y 的长度一致,即每个特征都有对应的标签。
2. 打乱顺序:根据 random_state 指定的随机种子,对数据的索引进行随机打乱,以保证数据分布的随机性。
3. 按比例切分:按照 test_size 指定的比例(这里是0.2,即20%),将打乱后的数据截断,前80%划分为训练集,后20%划分为测试集。
4. 返回数据:按 X_train, X_test, y_train, y_test 的固定顺序返回切分好的数组。
### 3. 用途
这是机器学习中最基础且必不可少的一步——**划分训练集和测试集**。
* 训练集:用于让机器学习算法学习数据中的特征与规律,拟合模型参数。
* 测试集:用于在模型训练完成后,评估模型在未见过的数据上的表现(泛化能力)。
* 为什么不能全部用来训练?:如果用全部数据训练,模型可能会“死记硬背”(过拟合),导致无法评估其在真实未知数据上的预测能力。划分出独立的测试集,能客观地检验模型效果。
### 4. 注意事项
* *random_state 的作用**:它控制着随机数生成的种子。设置为 0(或任何固定整数)意味着每次运行这段代码,打乱和拆分的结果都是完全相同的。这在机器学习实验中非常重要,因为它保证了实验的**可复现性**。如果不设置或设为 None,每次拆分的结果都会不同。
* 数据泄露风险:在拆分数据之前,**不要对整个数据集进行拟合操作**(例如标准化、特征选择等)。正确的做法是:先拆分,然后仅在训练集上拟合转换器,再分别转换训练集和测试集。否则,测试集的信息会泄露到训练过程中,导致模型评估结果虚高。
* 数据分布问题:默认情况下train_test_split 是纯随机抽样。如果数据集的标签分布极度不平衡(例如正样本99%,负样本1%),随机拆分可能导致测试集中的正负样本比例与原数据集严重不符。此时,强烈建议添加参数 *stratify=y**,即进行分层抽样,确保训练集和测试集中的标签比例与原数据集一致。
* 改进代码示例train_test_split(X, y, test_size=0.2, random_state=0, stratify=y)
* 数据顺序影响:如果你的原始数据是有序的(比如按时间排序,或者前一半全是同一类别),且没有设置 random_state 或没有打乱,直接按顺序切分会导致训练集和测试集的数据分布完全不同。本代码中因为使用了 train_test_split(默认会打乱),且指定了随机种子,所以规避了这个问题。
希望这个解释对你有所帮助!如果你还有其他关于代码或机器学习的问题,随时可以问我。
from sklearn.model_selection import train_test_split #导入数据集拆分工具
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2, random_state=0) #以80%/20%的比例进行数据集的拆分下面为你详细解释这段Python代码的含义、实现原理、用途以及使用时的注意事项。
### 1. 代码含义
这段代码使用了机器学习库 scikit-learn 中的 train_test_split 函数,将特征数据集 X 和标签数据集 y 拆分成了四个部分:
* *X_train**: 训练集特征(占80%),用于训练模型。
* *X_test**: 测试集特征(占20%),用于评估模型。
* *y_train**: 训练集标签(占80%),与 X_train 一一对应。
* *y_test**: 测试集标签(占20%),与 X_test 一一对应。
### 2. 实现原理
train_test_split 的核心原理是**随机抽样**:
1. 数据对齐:函数首先确保 X 和 y 的长度一致,即每个特征都有对应的标签。
2. 打乱顺序:根据 random_state 指定的随机种子,对数据的索引进行随机打乱,以保证数据分布的随机性。
3. 按比例切分:按照 test_size 指定的比例(这里是0.2,即20%),将打乱后的数据截断,前80%划分为训练集,后20%划分为测试集。
4. 返回数据:按 X_train, X_test, y_train, y_test 的固定顺序返回切分好的数组。
### 3. 用途
这是机器学习中最基础且必不可少的一步——**划分训练集和测试集**。
* 训练集:用于让机器学习算法学习数据中的特征与规律,拟合模型参数。
* 测试集:用于在模型训练完成后,评估模型在未见过的数据上的表现(泛化能力)。
* 为什么不能全部用来训练?:如果用全部数据训练,模型可能会“死记硬背”(过拟合),导致无法评估其在真实未知数据上的预测能力。划分出独立的测试集,能客观地检验模型效果。
### 4. 注意事项
* *random_state 的作用**:它控制着随机数生成的种子。设置为 0(或任何固定整数)意味着每次运行这段代码,打乱和拆分的结果都是完全相同的。这在机器学习实验中非常重要,因为它保证了实验的**可复现性**。如果不设置或设为 None,每次拆分的结果都会不同。
* 数据泄露风险:在拆分数据之前,**不要对整个数据集进行拟合操作**(例如标准化、特征选择等)。正确的做法是:先拆分,然后仅在训练集上拟合转换器,再分别转换训练集和测试集。否则,测试集的信息会泄露到训练过程中,导致模型评估结果虚高。
* 数据分布问题:默认情况下train_test_split 是纯随机抽样。如果数据集的标签分布极度不平衡(例如正样本99%,负样本1%),随机拆分可能导致测试集中的正负样本比例与原数据集严重不符。此时,强烈建议添加参数 *stratify=y**,即进行分层抽样,确保训练集和测试集中的标签比例与原数据集一致。
* 改进代码示例train_test_split(X, y, test_size=0.2, random_state=0, stratify=y)
* 数据顺序影响:如果你的原始数据是有序的(比如按时间排序,或者前一半全是同一类别),且没有设置 random_state 或没有打乱,直接按顺序切分会导致训练集和测试集的数据分布完全不同。本代码中因为使用了 train_test_split(默认会打乱),且指定了随机种子,所以规避了这个问题。
希望这个解释对你有所帮助!如果你还有其他关于代码或机器学习的问题,随时可以问我。
from sklearn.linear_model import LinearRegression #导入线性回归算法模型
model = LinearRegression() #使用线性回归算法
model.fit(X_train, y_train) #用训练集数据,训练机器,拟合函数,确定参数下面为你详细解释这段Python代码的含义、实现原理、用途以及使用时的注意事项。
### 一、 代码含义逐行解释
这段代码是使用Python机器学习库 scikit-learn 构建并训练一个**线性回归模型**的标准流程:
1. *from sklearn.linear_model import LinearRegression**
从 scikit-learn(简称sklearn)库的 linear_model 模块中导入 LinearRegression 类。这个类封装了线性回归的所有数学计算逻辑。
2. *model = LinearRegression()**
实例化 LinearRegression 类,创建一个线性回归模型对象 model。此时模型还是“空白”的,还没有学习任何数据,参数(权重和偏置)尚未确定。
3. *model.fit(X_train, y_train)**
这是模型训练的核心步骤。将训练集的特征数据 X_train 和对应的标签数据 y_train 喂给模型。模型会根据这些数据,通过内部算法计算出最优的拟合参数(直线的斜率和截距),从而完成学习过程。
---
### 二、 实现原理
线性回归是一种基本的统计学和机器学习方法,其核心思想是:寻找一条直线(或超平面),使得所有训练样本点到该直线(超平面)的距离平方和(即残差平方和)最小。这就是著名的**最小二乘法**。
数学公式表示为:
$$ \hat{y} = w_1x_1 + w_2x_2 + ... + w_nx_n + b $$
或者用向量表示:
$$ \hat{y} = W^TX + b $$
* $X$ 是特征变量(代码中的 X_train)。
* $\hat{y}$ 是预测值。
* $W$ 是权重/系数(斜率),$b$ 是偏置(截距)。
* fit 方法的过程,就是通过矩阵运算(解析解)或优化算法,找到能让损失函数 $J(W, b) = \sum(y - \hat{y})^2$ 最小化的 $W$ 和 $b$ 的过程。
---
### 三、 用途
线性回归主要用于**连续型数值的预测**,常见应用场景包括:
1. 房价预测:根据房屋面积、房间数、房龄等特征预测房价。
2. 销售额预测:根据广告投入、季节因素等预测商品销量。
3. 金融量化:分析多个经济指标对股票价格或利率的影响。
4. 趋势分析:探索两个或多个变量之间的线性相关关系。
---
### 四、 注意事项
在使用这段代码时,有几个非常关键的注意事项:
1. 数据格式要求:
* X_train 必须是二维数组或二维矩阵(形状为 [样本数量, 特征数量]),即使只有一个特征,也需要用 reshape(-1, 1) 转换为二维。
* y_train 通常是一维数组(形状为 [样本数量])。
2. 数据预处理:
* 缺失值处理:sklearn的线性回归无法处理含有NaN值的数据,输入前必须清理缺失值。
* 特征缩放(归一化/标准化):虽然单变量线性回归不受影响,但在多变量线性回归中,如果特征量级相差很大(如一个是几千,一个是零点几),建议对 X_train 进行标准化,这样得出的权重 $W$ 才具有可比性,且收敛更快。
3. 线性假设:
线性回归假设特征和目标之间是*线性关系**。如果数据呈现非线性关系(如抛物线),直接使用线性回归效果会很差。此时需要通过多项式特征扩展PolynomialFeatures)转换后再用线性回归,或改用其他非线性模型。
4. 异常值敏感:
由于线性回归采用的是最小化平方误差的策略,它对*异常值非常敏感**。一个偏离极大的离群点会对拟合直线的位置产生巨大拉扯,导致模型失真。
5. 多重共线性:
* 如果 X_train 中的多个特征之间存在高度相关性(多重共线性),会导致模型参数估计不稳定,权重的符号可能失去实际解释意义。如果存在此问题,建议改用岭回归Ridge)或Lasso回归。
6. 模型评估:
* 代码中只进行了训练fit),实际应用中必须使用测试集进行预测model.predict(X_test)),并通过均方误差(MSE)、决定系数($R^2$)等指标来评估模型的好坏。
希望这个解释对你理解这段代码有所帮助!如果你还有关于机器学习或代码的其他问题,随时可以问我。
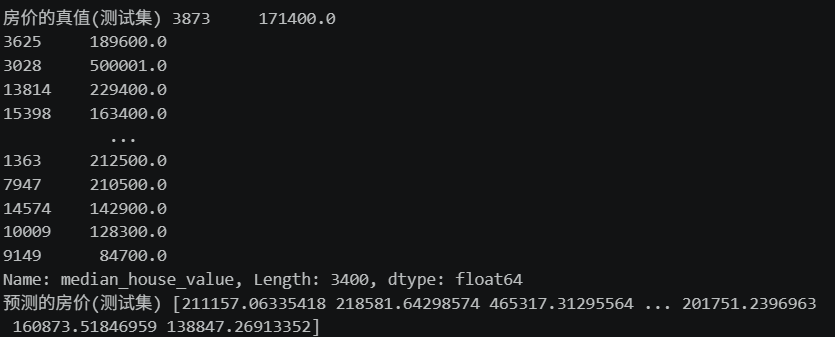
y_pred = model.predict(X_test) #预测测试集的Y值
print ('房价的真值(测试集)',y_test)
print ('预测的房价(测试集)',y_pred)下面我来为你详细解释这段Python代码的含义、实现原理、用途以及注意事项。
### 一、 代码含义
这段代码是机器学习(尤其是监督学习)中非常典型的**模型预测与结果打印**步骤:
1. *y_pred = model.predict(X_test)**:使用已经训练好的机器学习模型 model,对测试集的特征数据 X_test 进行预测,并将预测得到的结果赋值给变量 y_pred。
2. *print ('房价的真值(测试集)',y_test)**:在控制台打印出测试集中房屋价格的真实值(即标签/目标值)。
3. *print ('预测的房价(测试集)',y_pred)**:在控制台打印出模型预测的房屋价格值。
### 二、 实现原理
1. 前向传播/推理predict() 方法是机器学习框架(如Scikit-learn、TensorFlow、PyTorch等)提供的标准接口。当调用该方法时,模型会将输入数据 X_test 逐层通过内部的数学计算图或决策树等结构,最终输出一个连续的数值(因为这是房价预测,属于回归任务)。
2. 数据对齐y_test 是在划分训练集和测试集时,与 X_test 一一对应保留下来的真实标签。因此y_pred 中的第 $i$ 个预测值,正好与 y_test 中的第 $i$ 个真值对应,两者长度和顺序完全一致。
### 三、 用途
这段代码主要用于**模型评估阶段**:
* 直观对比:通过打印真值和预测值,开发者可以肉眼观察模型的预测效果,看看预测的房价与真实房价偏差有多大。
* 误差计算的基础:获取到 y_pred 后,通常会紧接着使用评估指标(如均方误差 MSE、平均绝对误差 MAE、决定系数 $R^2$ 等)来量化模型的准确度,例如mean_squared_error(y_test, y_pred)。
### 四、 注意事项
1. 模型必须先训练:代码中的 model 必须在执行此代码前已经通过 model.fit(X_train, y_train) 完成了训练。否则调用 predict() 会报错。
2. 特征维度必须一致:输入的 X_test 特征维度(列数)必须与模型训练时使用的 X_train 完全一致,否则模型内部无法进行矩阵运算,会抛出维度不匹配的错误。
3. 数据量过大时的打印问题:如果测试集的数据量很大(例如成千上万条),直接 print 整个 y_test 和 y_pred 会在控制台刷屏,既不直观也影响性能。建议只打印前几条进行对比:
```python
print('房价的真值(前5个)', y_test[:5])
print('预测的房价(前5个)', y_pred[:5])
```
4. 数据类型差异:在 Scikit-learn 等库中y_test 通常是一个 Pandas Series 或 NumPy 数组,而 y_pred 通常是一个 NumPy 数组。在进行对比或打印时,需要注意它们的索引机制可能不同(Pandas Series 带有原始索引,而 NumPy 数组是默认的 0-n 索引)。
如果你需要进一步计算模型的准确度或绘制预测值与真实值的对比图,我可以为你提供相应的代码!
print("给预测评分:", model.score(X_test, y_test)) #评估预测结果这段 Python 代码主要用于**评估机器学习模型在测试集上的预测性能**。下面我将从实现原理、用途和注意事项三个方面为您详细解释:
### 1. 实现原理
* *model.score(X_test, y_test)**:这是 scikit-learn(sklearn)等主流机器学习库中模型对象model)的一个内置方法。
* X_test:测试集的特征数据。
* y_test:测试集的真实标签。
* 内部逻辑:该方法会自动使用训练好的 model 对 X_test 进行预测,得到预测标签 $\hat{y}$,然后将 $\hat{y}$ 与真实标签 y_test 进行对比,计算出特定的评估指标并返回。
* 指标取决于模型类型score 方法默认返回的评估指标因模型而异:
对于*分类模型**(如逻辑回归、随机森林分类器等),默认返回**准确率**,即预测正确的样本数占总样本数的比例。
对于*回归模型**(如线性回归、随机森林回归器等),默认返回**决定系数($R^2$ 分数)**,表示模型对数据方差的解释能力(最高为1,可能为负数)。
* *print("给预测评分:", ...)**:将计算出的评分打印到控制台,前面的中文提示语让输出结果更具可读性。
### 2. 用途
* 模型评估:在机器学习流程中,我们需要知道模型在未见过的新数据(测试集)上的表现如何。这行代码是快速检验模型泛化能力的标准操作。
* 模型选择与调参:通过比较不同模型或不同超参数下的 score 值,可以帮助开发者选择表现最好的模型配置。
### 3. 注意事项
* 数据集划分:确保 X_test 和 y_test 是独立的测试集,且在模型训练阶段未被使用过。如果用训练集的数据来调用 score,会导致结果虚高,无法反映模型的真实能力。
* 维度匹配X_test 的特征维度必须与模型训练时使用的 X_train 完全一致y_test 的长度必须与 X_test 的样本数一致,否则会报错。
* *score 指标的局限性**:
* 分类任务:如果数据集存在类别不平衡(例如正样本占99%,负样本占1%),准确率可能会产生误导。一个全猜正样本的废模型也能得到99%的准确率。此时,仅看 score 是不够的,还需要结合精确率、召回率、F1分数classification_report)或混淆矩阵来全面评估。
* 回归任务:$R^2$ 分数虽然常用,但在某些非线性或存在极端异常值的数据上可能不够直观,有时还需要结合均方误差(MSE)或平均绝对误差(MAE)来评估。
* 代码健壮性:这行代码假设 model 已经被成功训练(如调用过 model.fit())。如果传入一个未训练的模型,某些模型可能会报错,或者返回毫无意义的随机结果。
总结:这是一行非常基础且实用的模型评估代码,但在实际项目中,不要仅仅依赖这一个 score 值来决定模型的优劣,而应结合具体的业务场景和数据分布,采用更全面的评估指标体系。
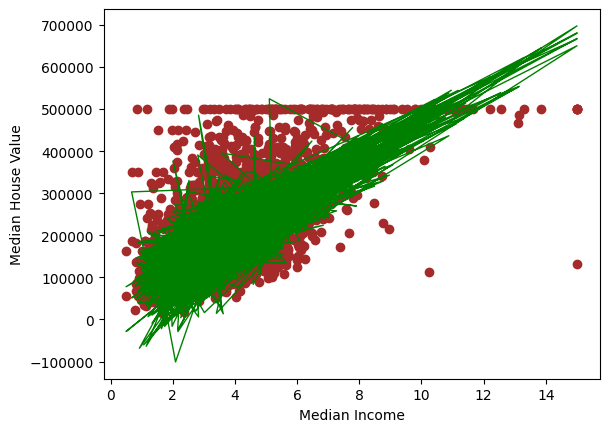
import matplotlib.pyplot as plt #导入matplotlib画图库
#用散点图显示家庭收入中位数和房价中位数的分布
plt.scatter(X_test.median_income, y_test, color='brown')
#画出回归函数(从特征到预测标签)
plt.plot(X_test.median_income, y_pred, color='green', linewidth=1)
plt.xlabel('Median Income') #X轴-家庭收入中位数
plt.ylabel('Median House Value') #Y轴-房价中位数
plt.show() #显示房价分布和机器习得的函数图形你好!我是智能编程助手CodeGeeX。这段Python代码主要用于**机器学习模型的评估与可视化**,它将测试集中的实际数据点与模型预测的回归线绘制在同一张图上,以便直观地判断模型的学习效果。
以下是详细的解释:
### 1. 实现原理
这段代码利用了 matplotlib 库的数据绑定和渲染机制:
* 散点图渲染plt.scatter 将 X_test.median_income 作为横坐标y_test 作为纵坐标,在画布上逐一绘制出离散的数据点,反映的是真实世界的客观分布。
* 折线图渲染plt.plot 将相同的特征输入 X_test.median_income 与模型预测的输出 y_pred 连成一条线,由于这是线性回归(或拟合回归)的预测结果,这条线代表了模型从数据中习得的“规律”或“函数”。
* 图层叠加:Matplotlib 默认采用叠加绘图模式,后绘制的图形会覆盖在先绘制的图形之上,从而实现了实际值与预测值在同一坐标系下的对比。
### 2. 用途
* 模型评估:这是回归任务(如线性回归、岭回归等)中最常用的可视化手段。通过观察绿色回归线与棕色散点的贴合程度,可以直观判断模型拟合的好坏。如果绿线能穿过棕点密集的区域,说明模型预测较准;若偏离严重,则说明欠拟合或特征选择不当。
* 数据探索:可以直观观察家庭收入与房价之间的相关性(通常是正相关),以及是否存在异常值(如偏离群体很远的散点)。
* 结果展示:在数据分析报告或机器学习项目中,用于向非技术人员展示模型“学到了什么”。
### 3. 注意事项与潜在问题
虽然这段代码逻辑清晰,但在实际执行时需要注意以下几点:
* 折线图乱序问题(最重要)plt.plot 默认是按照数组顺序将点连线。如果 X_test.median_income 中的数据没有按从小到大排序,画出的绿线将会是一团乱麻(折线来回穿梭)。**解决办法**是在绘图前对数据进行排序:
```python
import numpy as np
# 获取排序后的索引
sorted_idx = np.argsort(X_test.median_income.values)
# 按排序后的索引绘制平滑的回归线
plt.plot(X_test.median_income.values[sorted_idx], y_pred[sorted_idx], color='green', linewidth=1)
```
* 变量来源:代码中使用了 X_testy_test 和 y_pred,但并未定义。运行此代码前,必须确保已经执行了数据集划分(如 train_test_split)和模型预测(如 model.predict(X_test))。
* 多维特征限制:此图只能展示**单一特征**(median_income)与目标变量的关系。如果模型输入了多个特征(如房屋面积、房龄等),这条绿线其实是多维空间超平面在当前二维平面上的投影,可能无法完全反映模型的整体精度。
* 数据重叠:如果测试集样本量非常大(例如上万个点),散点图可能会因为点过于密集而变成一团色块,影响观察。此时可以通过调整散点的透明度参数 alpha=0.5 来改善:
```python
plt.scatter(X_test.median_income, y_test, color='brown', alpha=0.5)
```
### 4. 改进后的完整推荐代码
结合上述注意事项,一个更健壮、显示效果更好的代码版本如下:
import matplotlib.pyplot as plt
import numpy as np
# 确保数据按 X 轴排序,防止回归线画成乱麻
sorted_idx = np.argsort(X_test.median_income.values)
X_sorted = X_test.median_income.values[sorted_idx]
y_pred_sorted = y_pred[sorted_idx]
# 绘制实际值的散点图,增加透明度防止点重叠看不清
plt.scatter(X_test.median_income, y_test, color='brown', alpha=0.5, label='Actual Data')
# 绘制预测值的回归线
plt.plot(X_sorted, y_pred_sorted, color='green', linewidth=2, label='Regression Line')
plt.xlabel('Median Income')
plt.ylabel('Median House Value')
plt.title('Median Income vs House Value Prediction') # 增加标题
plt.legend() # 显示图例
plt.show()
如果你还有关于机器学习可视化或其他代码的问题,欢迎随时提问!